
tg-me.com/ds_interview_lib/287
Last Update:
Объясните, как работает Transformer?
Архитектура Transformer используется преимущественно в языковых моделях. Их обучают на большом количестве текстов. Наиболее известная задача, в которой используются такие модели, это, конечно, генерация новых текстов. Нейросеть должна предсказать следующее слово в последовательности, отталкиваясь от предыдущих. Transformer же изначально был разработан для перевода.
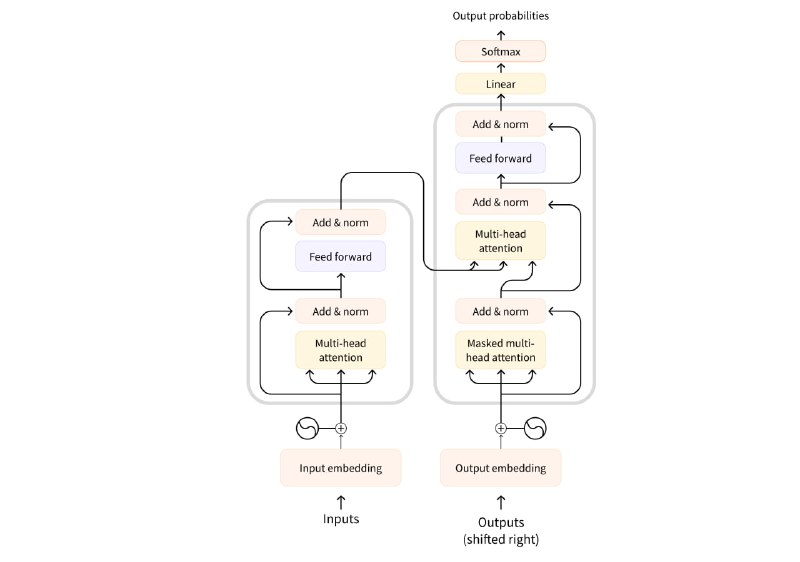
Его архитектура состоит из двух основных блоков:
▪️Энкодер (Encoder) (слева).
Этот блок получает входные данные (инпут) и создаёт их представления в векторном пространстве.
▪️Декодер (Decoder) (справа).
Этот блок использует представления, полученные от энкодера, а также другие входные данные, чтобы сгенерировать последовательность.
Основная фишка архитектуры Transformer заключается в наличии специального слоя — attention. Этот слой как бы указывает модели обращать особое внимание на определённые слова в последовательности. Это позволяет более эффективно обрабатывать контекст и улавливать сложные зависимости в тексте.
Во время обучения Transformer энкодер получает инпут (предложение) на определённом языке. Декодеру дают то же предложение, но на другом, целевом, языке. В энкодере слой attention может использовать все слова в предложении для создания контекстуализированного представления каждого слова, а декодер использует информацию об уже сгенерированных словах для предсказания следующего слова в последовательности.
В целом, ключевой особенностью механизма attention является его способность динамически фокусироваться на различных частях входной последовательности при обработке каждого слова, что позволяет модели лучше понимать контекст и нюансы языка.
#глубокое_обучение
#NLP
BY Библиотека собеса по Data Science | вопросы с собеседований
Share with your friend now:
tg-me.com/ds_interview_lib/287